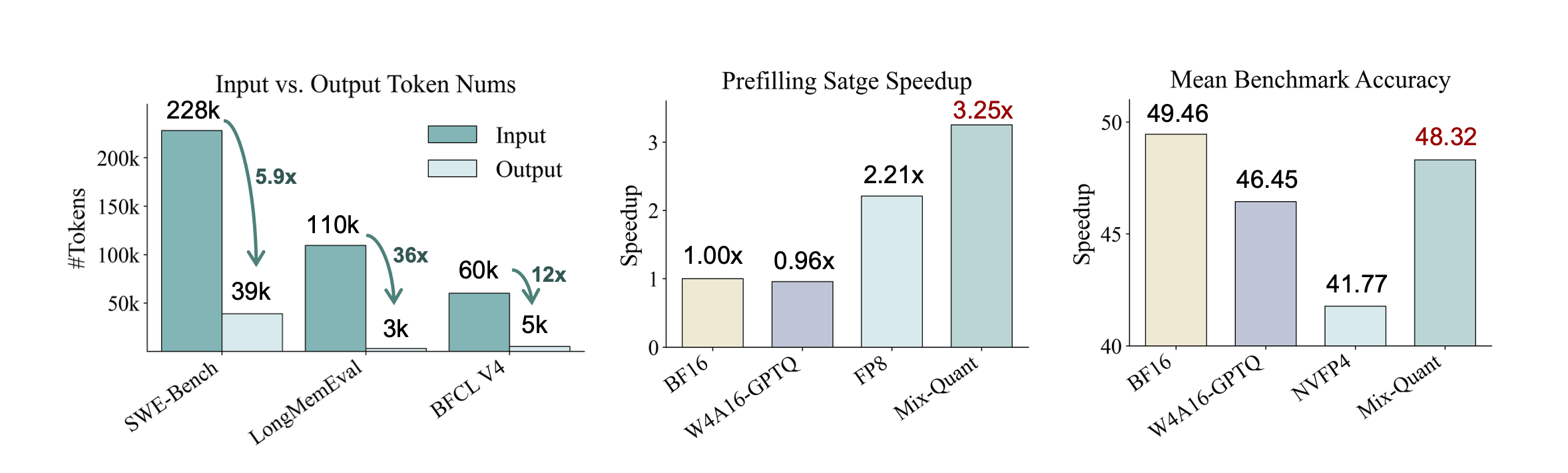
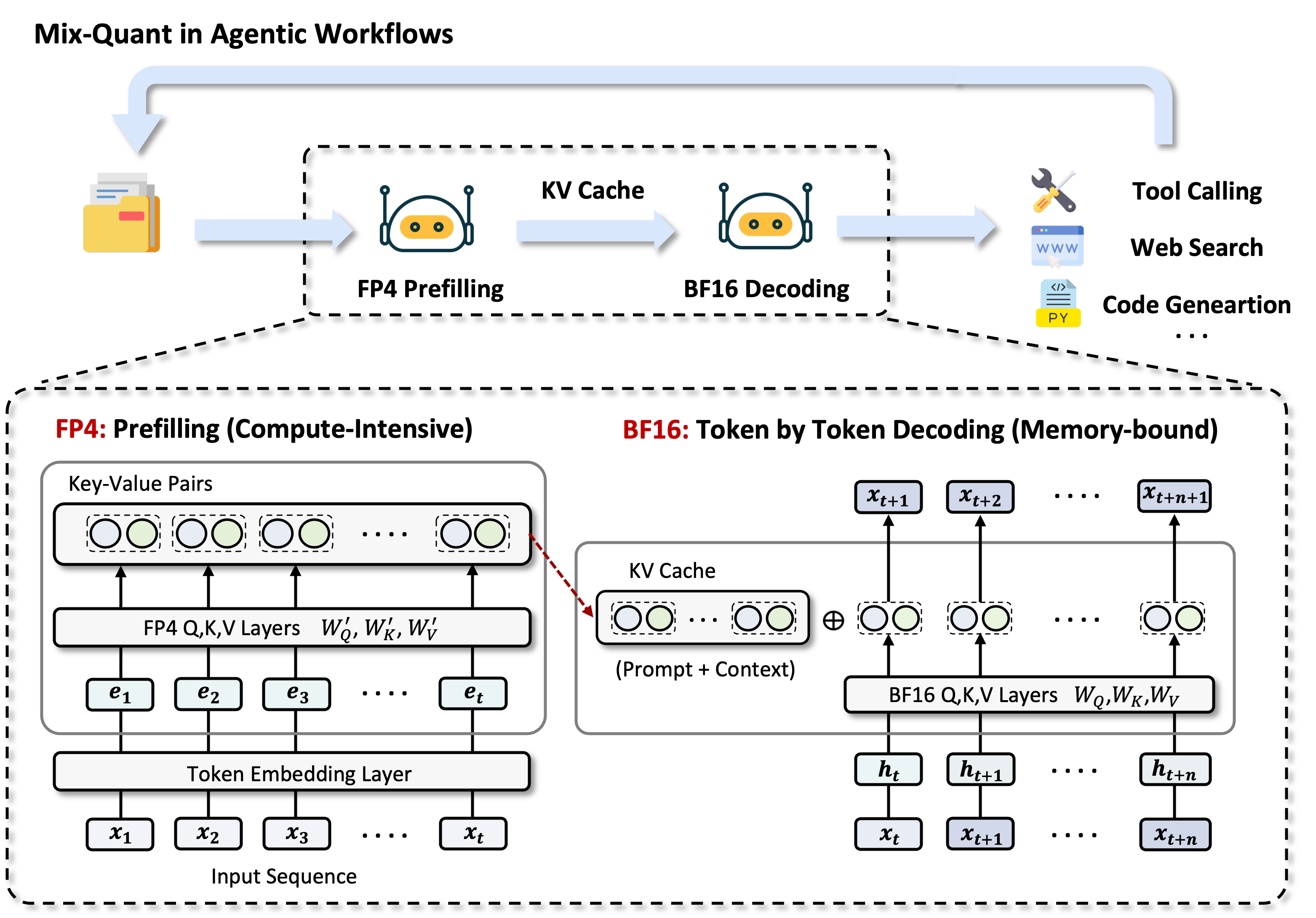
LLM agents have recently emerged as a powerful paradigm for solving complex tasks through planning, tool use, memory retrieval, and multi-step interaction. However, these agentic workflows often introduce substantial input-side overhead, making the compute-intensive prefilling stage a key bottleneck in long-context, multi-turn inference.
In this work, we propose Mix-Quant, a simple and effective phase-aware quantization framework for fast agentic inference. We first investigate FP4 quantization in agentic LLM workflows and observe that quantizing the entire inference process can incur significant performance degradation. In contrast, the prefilling stage exhibits substantial quantization redundancy and can therefore be quantized with minimal accuracy loss, despite being the dominant source of computation. Based on this insight, we apply high-throughput NVFP4 quantization to the prefilling phase while preserving BF16 precision for decoding. By decoupling prefilling acceleration from decoding quality, Mix-Quant combines phase-aware algorithmic quantization with hardware-efficient NVFP4 execution to alleviate the inference bottleneck in LLM agents.
Extensive experiments across long-context and agentic benchmarks demonstrate that Mix-Quant largely preserves task performance while delivering significant efficiency improvements, achieving up to a 3x speedup during prefilling.